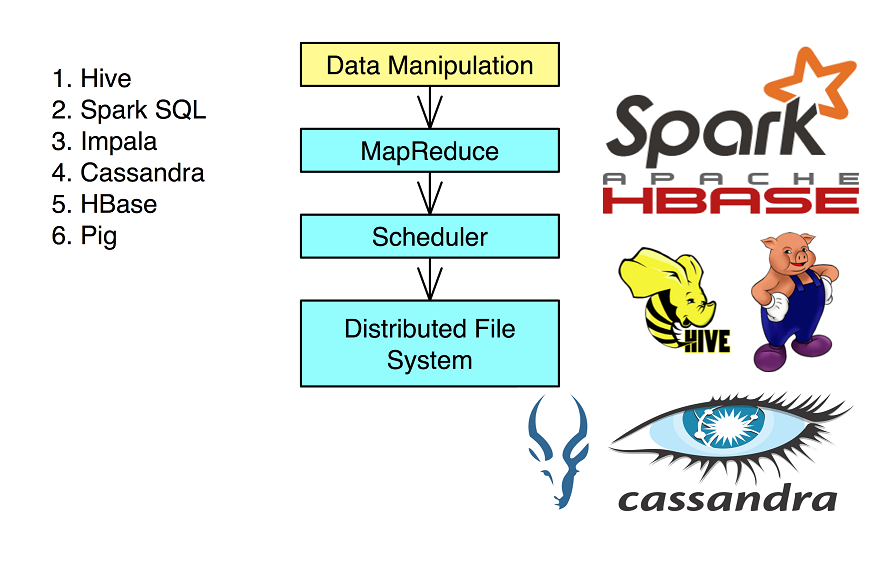
Apache Spark in Big Data Engineering
Phython Scientic Stack in Data Science
Hadoop for Data Science
Data warehouse
NoSQL
Tableau
Kafka
Mathematica
Hadoop for Streaming, Spark, Storm, Kafka
Hadoop for Data Analysis
——————————
Commodity hardware:
standard hardware that is relatively inexpensive/affordable,
home PC like widely available
low-performance system in general
less interchangeable with other hardware of its type
(Downside???? failures are common)
How to interact with YARN (Yet Another Resource Negotiator) and HDFS (Hadoop Distributed File System)?
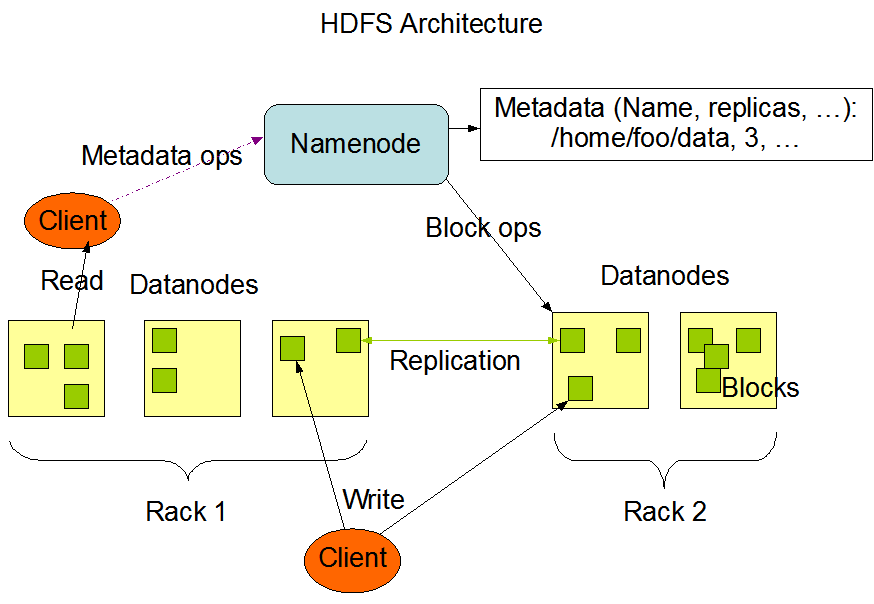
HDFS
Hadoop Distributed File System
Primary storage system used by Hadoop clusters
Provides high-performance access to big data
Since deployed on commodity hardware, server failures are common so is failure of the nodes.
Multiple nodes provide computing resources and continuation in operation even on some failures.
HDFS breaks the information (data volume) down into separate pieces and distributes them to different nodes in a cluster, allowing for parallel processing.
The file system also copies each piece of data multiple times and distributes the copies to individual nodes, placing at least one copy on different server.
As a result, the data on nodes that crash can be found elsewhere within a cluster, which allows processing to continue while the failure is resolved.
HDFS operates in a master/slave architecture;
Single NameNode = managing file system operations
Multiple DataNodes = managing data storage on individual compute nodes
hortonworks.com/downloads
Hadoop includes:
HDFS – A distributed file system (similar to GFS) that provides high throughput access to application data
HBase – A scalable, distribution database (similar to Bigtable) that supports structured data storage for large tables.
MapReduce – A software framework for distributed processing of large data sets on compute clusters
Hadoop Common – the common utilities that support the Hadoop subprojects
Chukwa – A data collection system for managing large distributed systems.
Pig – A high level data flow language and execution framework for parallel computation (that produces a sequence of MapReduce programs)
ZooKeeper – A high performance co-ordination service for distributed applications.
JVM: A Java virtual machine is a virtual machine that can execute Java bytecode
Understanding how information is stored and processed in servers is important. Hadoop does most of things for us.
HDFS is Hadoop’s file system – Hadoop Distributed File System while MapReduce is its processing engine and there are many libraries and programming tools to support Hadoop in Big Data.
Set up a Hadoop development environment, run and optimize MapReduce jobs; and then do the basics with Hive and Pig (query languages) followed by some job schedules with a workflow.
Topics include:
Understanding Hadoop core components: HDFS and MapReduce
Setting up your Hadoop development environment
Working with the Hadoop file system
Running and tracking Hadoop jobs
Tuning MapReduce
Understanding Hive and HBase
Exploring Pig tools
Building workflows
Using other libraries, such as Impala, Mahout, and Storm
Understanding Spark
Visualizing Hadoop output
Differences between Hadoop and HBase
Hadoop core ecosystem: HDFS (file system) + MapReduce (processing framework)
Each file is replicated 3 times in the Hadoop ecosystem on three different pieces of commodity hardware. HDFS files are by default 64 MB or 128 MB chunks and even can be configured for higher size chunks. These chunks are fed into the MapReduce framework.
MapReduce framework is written in the Java Programming Language (and may also be in other languages.) In fact, MapReduce to Hadoop is what C++ to OOP (Object Oriented programming.)
Hadoop is criticized by some who don’t want to work at this level of abstraction being limited to Java. People might want to work at a level that is more accessible by more people in your organization.
HBase is a library that provides a solution to working with the Hadoop system. This is like a wide column store – one ID column and the other data column — since there is no requirement for any particular values in the data column it’s called wide column.
Schema on read: we need to impose some sort of schema in order to query or get the information out but not when we put the information in.
Hadoop File Systems
HDFS (Hadoop Distributed File System) – triple replicated by default.
Fully distributed: 3 copies
Pesudo distributed: single copy on a single machine, only for testing
As an alternative to HDFS, Hadoop also supports Regular File System – Standalone mode. This should be a great start for the initial learning phase about MapReduce in Big Data to reduce the complexity itself by usinga regular file.
Operation of Hadoop:
1) Single Node mode: Deploying Hadoop in a Single node means using the local file system and a single JVM (Java Virtual machine) for all the Hadoop processes.
2) Pseudo-distributed mode: HDFS is used and Java daemons run all the processes on a single machine.
3) Fully-distributed mode: HDFS is used and everything is triple replicated, daemons run on various locations according to need.
Apache Hadoop Ecosystem Block Diagram (Open Source libraries)
Top is HDFS
MapReduce: Second core part of a Hadoop implementation, YARN (Yet Another Resource Negotiator)
Commercial version of Hadoop implementation may see different components or modules.
Hadoop Environment Setting
VM Guest OS: 4GB RAM, 3GB+ Disk space apart from OS’s installation size (minimum reqd)
Recommended reqd: At least 8 GB RAM (16 GB preferred) and a SSD of 128 GB.
Decision based on: How many Data nodes?
Best practice: 32GB RAM on a QuadCore machine for a Single Data node
How-to: Select the Right Hardware for Your New Hadoop Cluster
https://blog.cloudera.com/blog/2013/08/how-to-select-the-right-hardware-for-your-new-hadoop-cluster/
ETL: Extract, Transform, Load
Cloudera LIVE: http://goo.gl/9kWHRW