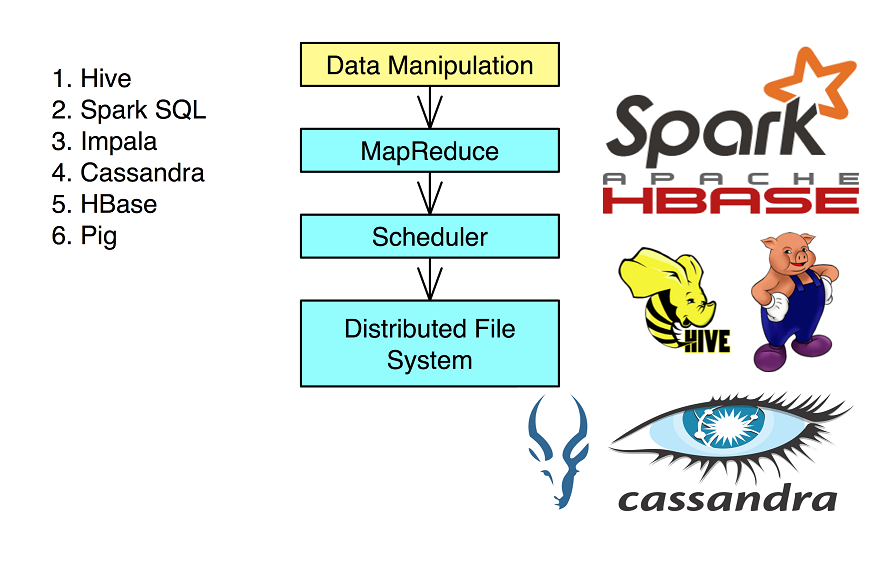
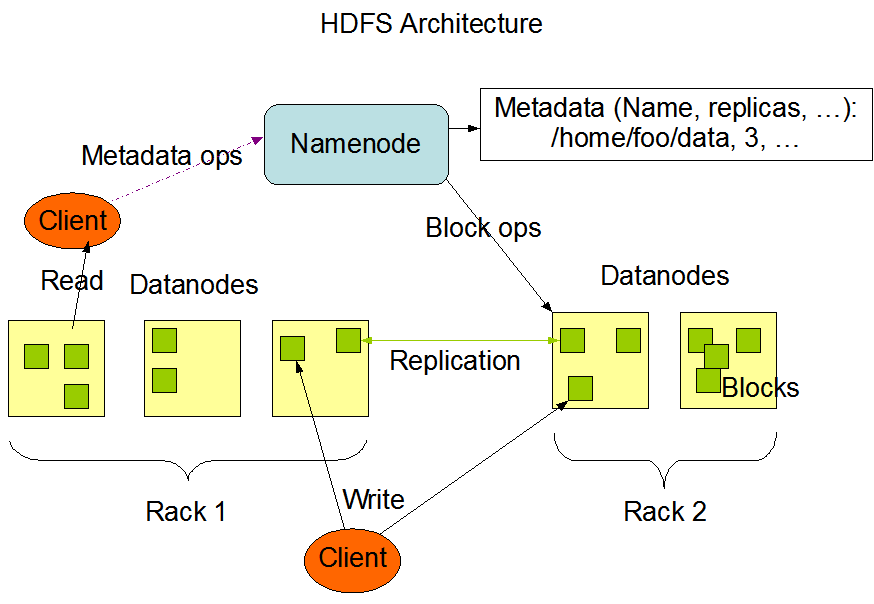
Understanding how information is stored and processed in servers is important. Hadoop does most of things for us. HDFS is Hadoop’s file system – Hadoop Distributed File System while MapReduce is its processing engine and there are many libraries and programming tools to support Hadoop in Big Data.
Set up a Hadoop development environment, run and optimize MapReduce jobs; and then do the basics with Hive and Pig (query languages) followed by some job schedules with a workflow.
Topics include:
- Understanding Hadoop core components: HDFS and MapReduce
- Setting up your Hadoop development environment
- Working with the Hadoop file system
- Running and tracking Hadoop jobs
- Tuning MapReduce
- Understanding Hive and HBase
- Exploring Pig tools
- Building workflows
- Using other libraries, such as Impala, Mahout, and Storm
- Understanding Spark
- Visualizing Hadoop output

Differences between Hadoop and HBase
Hadoop core ecosystem: HDFS (file system) + MapReduce (processing framework)
Each file is replicated 3 times in the Hadoop ecosystem on three different pieces of commodity hardware. HDFS files are by default 64 MB or 128 MB chunks and even can be configured for higher size chunks. These chunks are fed into the MapReduce framework.
MapReduce framework is written in the Java Programming Language (and may also be in other languages.) In fact, MapReduce to Hadoop is what C++ to OOP (Object Oriented programming.)
Hadoop is criticized by some who don’t want to work at this level of abstraction being limited to Java. People might want to work at a level that is more accessible by more people in your organization.
Schema on read: we need to impose some sort of schema in order to query or get the information out but not when we put the information in.
Hadoop File Systems
HDFS (Hadoop Distributed File System) – triple replicated by default.
Fully distributed: 3 copies
Pesudo distributed: single copy on a single machine, only for testing
As an alternative to HDFS, Hadoop also supports Regular File System – Standalone mode. This should be a great start for the initial learning phase about MapReduce in Big Data to reduce the complexity itself by usinga regular file.
Operation of Hadoop:
1) Single Node mode: Depoying Hadoop in a Single node means using the local file system and a single JVM (Java Virtual machine) for all the Hadoop processes.
2) Pseudo-distributed mode: HDFS is used and Java daemons run all the processes on a single machine.
3) Fully-distributed mode: HDFS is used and everything is triple replicated, daemons run on various locations according to need.
Top is HDFS
MapReduce: Second core part of a Hadoop implementation, YARN (Yet Another Resource Negotiator)
Commercial version of Hadoop implementation may see different components or modules.