Preparation for Big Data
0) Decide where to use the installation: a VM or your current OS (preferably Ubuntu), if using VM ensure Intel-VT and AMD-V Virtualization hardware extensions are enabled from the BIOS. (How to go to BIOS if your machine has UEFI firmware?)
1) Install a fresh Ubuntu OS (latest release or the latest LTS, change /etc/apt/sources.list to reflect your local ubuntu repository http://np.archive.ubuntu.com/ubuntu/
2) Check if not already install the latest version of Java Runtime Environment.
Check if you have Java installed on your system.
Terminal: java -version
If wrong version of Java is installed: sudo apt-get purge openjdk-\*
Completely remove the OpenJDK/JRE from your system and create a directory to hold your Oracle Java JDK/JRE binaries.
sudo mkdir -p /usr/local/java
wget -p /usr/local/java LINK_BELOW
http://sdlc-esd.oracle.com/ESD6/JSCDL/jdk/8u131-b11/d54c1d3a095b4ff2b6607d096fa80163/jre-8u131-linux-x64.tar.gz?GroupName=JSC&FilePath=/ESD6/JSCDL/jdk/8u131-b11/d54c1d3a095b4ff2b6607d096fa80163/jre-8u131-linux-x64.tar.gz&BHost=javadl.sun.com&File=jre-8u131-linux-x64.tar.gz&AuthParam=1500294806_06c12d94d081de7861a712452a47a2bc&ext=.gz
OR
http://javadl.oracle.com/webapps/download/AutoDL?BundleId=220305_d54c1d3a095b4ff2b6607d096fa80163
cd /usr/local/java
tar -xvzf jre-8u131-linux-x64.tar.gz (Cross-check the file name just downloaded)
cd /usr/local/java ls -a (confirming the Java extraction)
(useful: tar -czvf jre-8u131-linux-x64.tar.gz /usr/local/java)
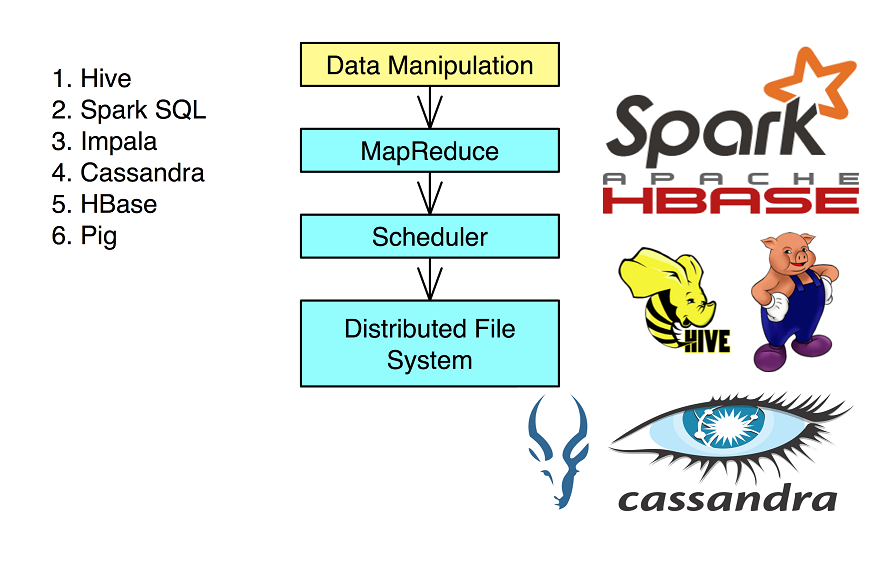
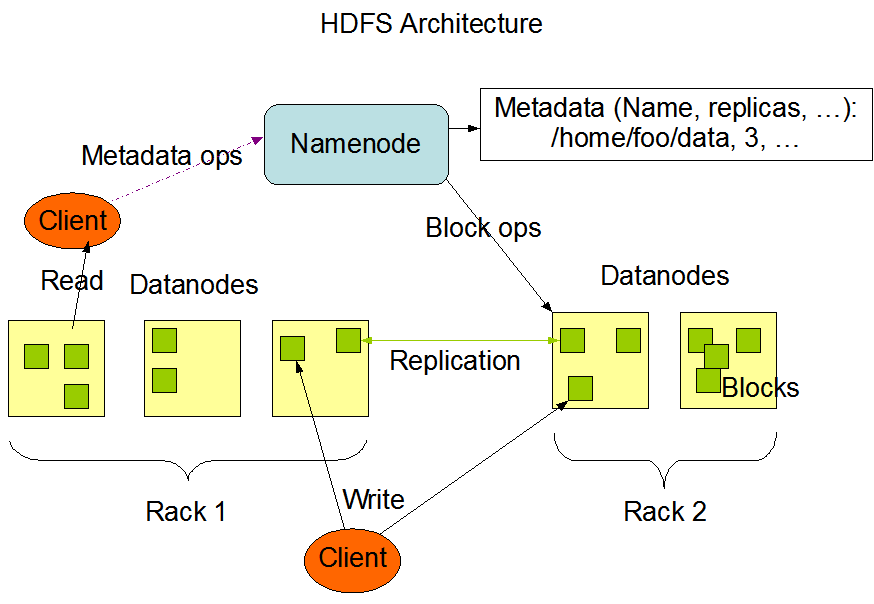
Hadoop’s HDFS is a highly fault-tolerant distributed file system and, like Hadoop in general, designed to be deployed on low-cost hardware. It provides high throughput access to application data and is suitable for applications that have large data sets.
Hadoop is a Java-based programming framework that supports the processing and storage of extremely large datasets on a cluster of inexpensive machines. It was the first major open source project in the big data playing field and is sponsored by the Apache Software Foundation.