
Elective : Big Data Technologies
Evaluation:
| Theory | Practical | Total | |
| Sessional | 30 | 20 | 50 |
| Final | 50 | – | 50 |
| Total | 80 | 20 | 100 |
Course Description:
The growth of information systems has given rise to large amount of data which do not qualify as traditional definition of data. This scenario has given us new possibilities but at same time pose serious challenges. Such challenges lies in effective storage, analysis and search of such large set of data. Fortunately, a number of technologies have been developed that answer such challenges. This course introduces this scenario along with technologies and how they answer these challenges.
Objective of the Course:
To introduce student to current scenarios of big data and provide various facets of big data. It also provides them with technologies playing key role in it and equips them with necessary knowledge to use them for solving various big data problems in different domains.
Course Contents
- Introduction to Big Data (8 Hours)
- Big Data Overview
- Background of Data Analytics
- Role of Distributed System in Big Data
- Role of Data Scientist
- Current Trend in Big Data Analytics
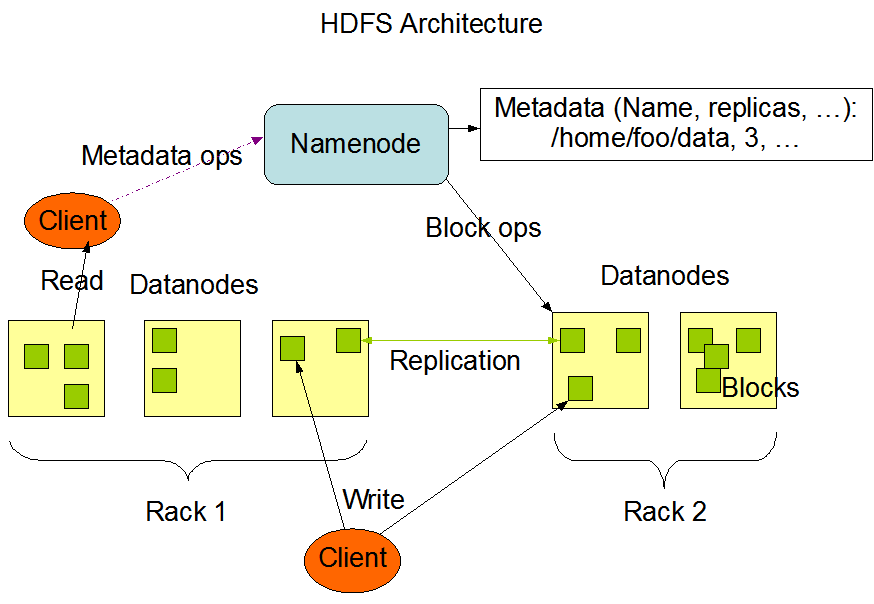
- Google File System (7 Hours)
- Architecture
- Availability
- Fault tolerance
- Optimization for large scale data
- Map-Reduce Framework (10 Hours)
- Basics of functional programming
- Fundamentals of functional programming
- Real world problems modeling in functional style
- Map reduce fundamentals
- Data flow (Architecture)
- Real world problems
- Scalability goal
- Fault tolerance
- Optimization and data locality
- Parallel Efficiency of Map-Reduce
- Basics of functional programming
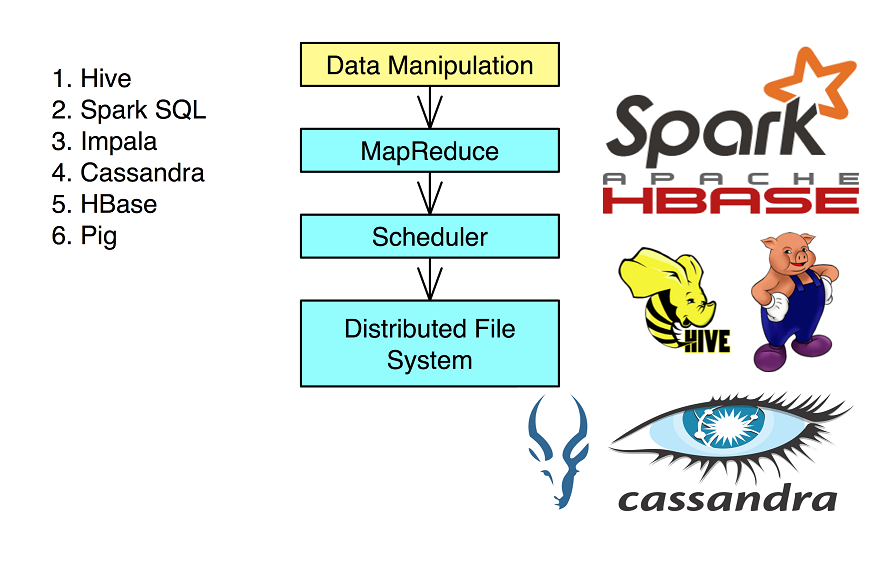
- NoSQL (6 Hours)
- Structured and Unstructured Data
- Taxonomy of NoSQL Implementation
- Discussion of basic architecture of Hbase, Cassandra and MongoDb
| 5 Searching and Indexing of Big Data 5.1 Full text Indexing and Searching 5.2 Indexing with Lucene 5.3 Distributed Searching with elastic search 5.4 | (7 Hours) |
| 6 Case Study: Hadoop 6.1 Introduction to Hadoop Environment 6.2 Data Flow 6.3 Hadoop I/O 6.4 Query languages for Hadoop 6.5 Hadoop and Amazon Cloud | (7 Hours) |
Practical
Student will get opportunity to work in big data technologies using various dummy as well as real world problems that will cover all the aspects discussed in course. It will help them gain practical insights in knowing about problems faced and how to tackle them using knowledge of tools learned in course.
- HDFS: Setup a hdfs in a single node to multi node cluster, perform basic file system operation on it using commands provided, monitor cluster performance
- Map-Reduce: Write various MR programs dealing with different aspects of it as studied in course 3. Hbase: Setup of Hbase in single node and distributed mode, write program to write into hbase and query it
- Elastic Search: Setup elastic search in single mode and distributed mode, Define template, Write data in it and finally query it
- Final Assignment: A final assignment covering all aspect studied in order to demonstrate problem solving capability of students in big data scenario.
References
- Jeffrey Dean, Sanjay Ghemawat, MapReduce:Simplified Data Processing on Large Clusters
- Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung, The Google File System
- Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, and Robert E. Gruber, Bigtable: A Distributed Storage System for Structured Data
- http://hadoop.apache.org/
- http://hbase.apache.org/
- http://www.elasticsearch.org/guide/
- Tom White, Hadoop: The Definitive Guide
- Lars George, Hbase: The Definitive Guide
- Jason Rutherglen, Ryan Tabora, Jack Krupansky, Lucene and Solr: The Definitive Guide

Pingback: LES TIC I TAC – Blog marta